 Uneven sunlight illuminates colorful fibers of woven yarn.
Uneven sunlight illuminates colorful fibers of woven yarn.
You may already use some form of AI in your day-to-day workflow. You might use ChatGPT to ask questions and research new technologies or GitHub’s Copilot assistant to generate code. You may even use an editor like Cursor or Windsurf to orchestrate whole projects from scaffolding to self-debugging (Cursor recently announced Yolo Mode).
Some of the folks I know are skeptics of AI tools. Some are fans and advocates. Others are ambivalent and/or tired of the hype. Some, like me, have quietly used AI to be more productive while trying to maintain a healthy distance and skepticism. Whatever your stance, I think we’re past the point of writing off AI entirely.
My background is in business and software development, and until recently, I have mostly ignored AI (this is the first time I’m writing about it). I’m going to use some software jargon in this article—but I’ll try to keep it generally applicable when possible because I think it would be helpful for more non-developers to understand how software developers are using these tools in the real world.
There are many different camps that AI critics fall into, and most of them agree that “AI” (Generative AI and LLMs, more specifically) is real and useful. The topic of “AI Skepticism” has been broadly discussed recently in response to journalist Casey Newton, who wrote about it in December for his newsletter, Platformer:
The most persuasive way you can demonstrate the reality of AI, though, is to describe how it is already being used today. Not in speculative sci-fi scenarios, but in everyday offices and laboratories and schoolrooms. And not in the ways that you already know — cheating on homework, drawing bad art, polluting the web — but in ones that feel surprising and new.
Newton’s take is that there are two camps of AI Skepticism: those who think it’s fake and it sucks, and those who believe it’s real and dangerous. Newton puts himself in the latter and argues that it’s perilous to assume that AI is snake oil soon to join NFTs and the Metaverse in the dustbin of history. In response, many have argued that Newton oversimplified the nuanced concerns of AI skeptics.
Benjamin Riley, a former attorney and education researcher who writes about generative AI systems through the lens of cognitive science, listed nine branches of AI Skepticism in response to Newton, with a final catchall category to further demonstrate the diversity of the field. Among them are skeptics of AI in education (where Riley places himself), two camps of scientific skepticism, skeptics of AI’s use in art and literature, and many more. I think that most of Riley’s skeptics make good points, and none of them (with the exception of the “neo-Luddites,” who may fall into Newton’s first category) believe that AI is fake or that it sucks.
When skeptics criticize “AI,” they’re often speaking about specific concerns, and not of the technology as a whole. They’re concerned with the religious fervor of Silicon Valley tech bros, the hysteria of AI doomers, or AI’s technical limitations—the latter camp being the quickest to point out that when we say “AI,” we’re really talking about LLMs. Some fear how companies like OpenAI may reconfigure society around their business models. Others call out the baseless marketing claims they use to fundraise.
These are reasonable concerns, and as consumers, we shouldn’t use these technologies mindlessly. As developers, we should pay special attention to the potential harms. But we also shouldn’t ignore generative AI as it reconfigures our industry and skills. And we should learn as much as we can about these technologies so that we can criticize them effectively. As Simon Willison recently wrote in his excellent recap of things we learned about LLMs in 2024:
LLMs absolutely warrant criticism. We need to be talking through these problems, finding ways to mitigate them and helping people learn how to use these tools responsibly in ways where the positive applications outweigh the negative.
I like people who are skeptical of this stuff. The hype has been deafening for more than two years now, and there are enormous quantities of snake oil and misinformation out there. A lot of very bad decisions are being made based on that hype. Being critical is a virtue.
Despite all the hype, there are good applications for these tools, and developers are in a unique position to counter uninformed opinions and help decision-makers implement generative AI safely.
And the fact is, LLMs are getting pretty damn useful. When GitHub Copilot first came out, I had mixed feelings. It impressed me some of the time, like when it would suggest the automated tests I needed for some code I’d written. Other times, it got in my way, making irrelevant suggestions and breaking my already scant concentration. So, I turned it off and would check back in from time to time. But ChatGPT was genuinely useful as a research, prototyping, and debugging tool from the beginning, and it rapidly improved as OpenAI released new models throughout 2022-2023. Anthropic’s Claude caught on among developers in early 2024, and it’s still what I primarily use today.
While it seemed like breakthroughs in LLM research and training had slowed, they’ve increasingly become more context-aware, the costs of training and running them have dropped substantially (reducing the environmental impacts), and developer tooling has improved rapidly. Integrated code assistants like Cursor and Codeium rolled out project-aware agents capable of completing tasks end-to-end with the developer riding shotgun. Recently, GitHub released a similar multi-file editing feature called Copilot Edits and announced a free tier.
If you haven’t tried these new tools yet, you should. It’s not that they won’t make mistakes—they will—but I’ve found that, on balance, I work much faster with them than without them. And as I’ve learned how to use them effectively, the odds have improved.
As Simon Willison points out, “LLMs are power-user tools—they’re chainsaws disguised as kitchen knives.”:
They look deceptively simple to use—how hard can it be to type messages to a chatbot?—but in reality you need a huge depth of both understanding and experience to make the most of them and avoid their many pitfalls.
A chainsaw is an apt metaphor. Without thinking through each interaction, you’ll find that you’ve mutilated your favorite bonsai tree. You should have used shears instead.
Knowing when—and more importantly—when not to ask an LLM to generate code for you is an important skill that comes with practice. My purpose here is not to give specific techniques or advice about using these tools (I’m still learning myself), but there are some clear heuristics emerging, many of which are already common sense in software development.
Even without a code assistant, you won’t arrive at the right solution (or even solve the right problem!) without understanding your domain. The first step should always be to think about the design of your system and the problem you’re trying to solve. Basically, don’t outsource your thinking. While that may seem obvious, I’ve found that in practice, it’s much too easy to imbue the LLM with agency that it doesn’t have, and that problem has wide-reaching implications. The good news is that the AI is not an engineer—so your job is safe for now.
I was recently updating an open-source library that we maintain at my company, Honeybadger, where we help developers improve the reliability and performance of their web applications. We provide client-library packages that integrate with a bunch of different programming languages and web frameworks, and one of the languages we support is Elixir—a popular functional programming language built on top of Erlang, an ancient language created at Ericsson for the telecommunications industry. Honeybadger’s Elixir application monitoring software integrates with Elixir to help developers monitor and fix their applications in production.
I’d noticed that we weren’t testing on the latest version of Elixir, which is currently 1.17, and we were a few versions behind. It’s normally a quick fix to update our automated test suite to test our code against new versions when they’re released, but in this case, it surfaced a couple of test failures on the latest Elixir version. That meant that something had changed in the underlying platform that our code runs on. While I’ve worked with Elixir for years as a part of the service we provide at Honeybadger (and even made a tiny contribution to the language), it had been a while since I’d debugged a problem like this.
I knew that two tests were failing, both in our logger implementation—which basically listens for events from Elixir and reports them to Honeybadger to help developers understand what’s happening when their code executes. Elixir has a feature called “pattern matching,” which allows us to handle specific types of events—errors in this case—and the issue was that something had changed in the structure of the events, causing Elixir’s pattern matching to break. Something about the shape of the events had changed between Elixir versions 1.15 and 1.17. But what changed?
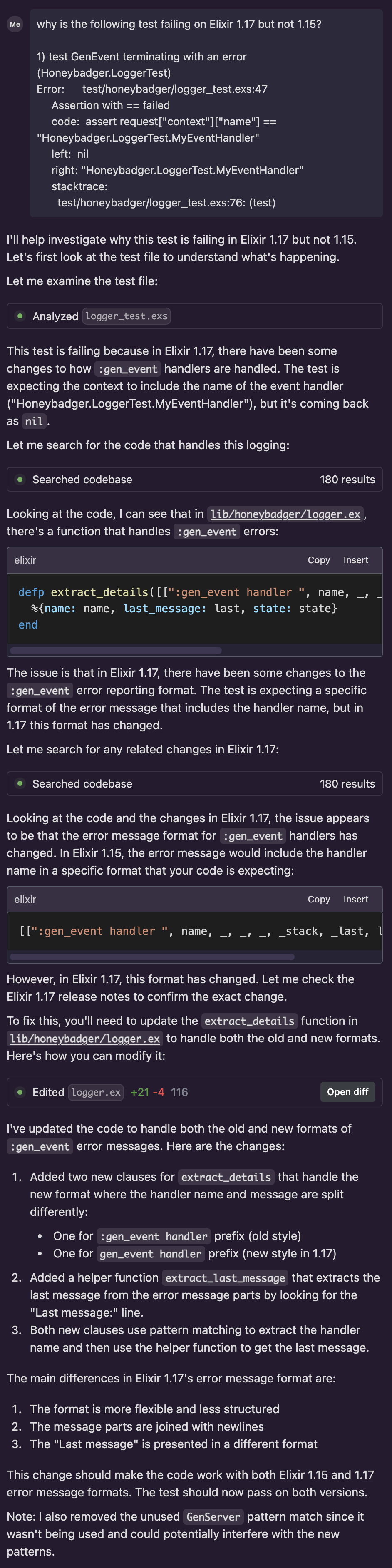
Since I’ve been experimenting with LLMs and code assistants, I decided to see if it could find the issue—so I copied the test failure output (which provides information about why the test is failing) and pasted it into Codium’s Windsurf editor (using Claude 3.5 Sonnet) and asked it what was causing the bug:
why is the following test failing on Elixir 1.17 but not 1.15?
1) test GenEvent terminating with an error (Honeybadger.LoggerTest)
Error: test/honeybadger/logger_test.exs:47
Assertion with == failed
code: assert request["context"]["name"] == "Honeybadger.LoggerTest.MyEventHandler"
left: nil
right: "Honeybadger.LoggerTest.MyEventHandler"
stacktrace:
test/honeybadger/logger_test.exs:76: (test)
What happened next was impressive. On the first try, it:
- Identified the failing test file
- Found the source file where the code was failing
- Explained the issue confidently, even referencing Elixir’s
1.17 release notes
- Proposed a change to the source file
The proposed change was small and looked incredibly reasonable at first glance; the solution was to expand the pattern-matching constraints so that the events from both Elixir versions would match. So I accepted it and ran the tests again, and they passed! I was impressed—this just saved me a bunch of time. After a few more exchanges, I fixed the second failing test (which was related), polished up the code a bit, and was almost done.
Of course, I wasn’t going to use this fix without documenting it first, so I asked Windsurf to summarize the conversation and actions it took, and it wrote it up for me. Everything looked good, so I committed (saved) the changes and pushed the code up to GitHub for a final review. The tests were now passing on all supported Elixir versions! But something didn’t feel right. Did I really understand the problem in the first place?
Normally, I would have started by debugging the data myself, which involves gathering more information, including what the events look like and how they changed between Elixir versions. I’d have spent more time reading the documentation and release notes for the failing Elixir versions. Only then would I have made a change to handle this specific scenario. I’d assumed Claude knew what it was talking about—it mentioned the release notes, after all—but how much knowledge was it really working with? It was hard to tell, and that’s a problem with LLMs: they’re a black box.
So I started from the beginning and soon discovered that there was just a small inconsistency in the structure of one particular event. Claude’s solution—expanding the constraints—did fix the bug, but it risked introducing new and more subtle bugs in the future when other events—events we don’t care about—could potentially invoke this code path. That would be bad, and what’s worse, if I continued to commit “fixes” like this, those changes would compound over time, reducing the quality and understanding of our codebase.
What I realized is that Claude was bullshitting me. It didn’t understand the underlying issue because it wasn’t actually described in the release notes. When it confidently identified the problem and proposed a solution, it had regurgitated the information I’d prompted it with, and I’d fallen for it. Oops.
In the end, I fixed the bug myself, and while it did involve changing some constraints, my solution addressed the root cause. Instead of just accepting more events, I added some specific handling (and documentation) for Elixir 1.17, leaving the old code path unchanged.
And that, dear reader, is how not to use an LLM.
LLMs themselves are confidently gullible pattern-matching engines that reflect our own thoughts back to us. But paradoxically, they’re also good at reasoning and making connections. This ability is useful in software development and also in figuring out what the hell people are talking about on the internet. But it also means that you shouldn’t trust them, and you definitely shouldn’t use them to replace your search engine or traditional research techniques.
Mike Caulfield, an online verification and information literacy researcher, is studying Claude’s ability to infer meaning and provide interpretive context. Search engines are backed by a database of known answers—not known to you (that’s why you’re searching for them)—but in general. They’re good at surfacing known unknowns. According to Caulfield, LLMs excel at the opposite: they surface unknown unknowns:
When you give these systems space to tell you (roughly) what’s in the linguistic vicinity of the linguistic representation of your problem, some pretty amazing things happen.
LLMs can help you understand your domain better and build up the context you need to solve problems faster—if you don’t let them beguile you. Code assistants and LLMs in general blur the lines between the two use cases, often pretending to be search engines when what you really want is to fill in the missing context. And what you ask them makes a difference:
What is striking is when you get over the idea of “give me this particular thing” and lean into “map out this issue using this lexically-inflected template for reasoning” it thinks up all the sorts of things you wouldn’t think to have asked.
In one experiment, Caulfield evaluated a TikTok video that used a newspaper article from 1928 to claim that the U.S. government had secretly funded the Wright Brothers before achieving flight in 1903, withholding technology from the public. The newspaper article claimed that the U.S. had spent billions on “aeronautics” since 1899—a claim that would be difficult for students to verify because the context needed to search for it is fuzzy. Instead of asking Claude for the answer directly, he fed it the video transcript and asked it to evaluate the evidence.
Claude’s response pointed out that a major war had occurred (WWI) between the Wright Brothers achieving flight in 1903 and the article’s date, and suggested learning how much aeronautical spending occurred prior to 1903 and whether it was connected to the Wright Brothers. Again, instead of asking Claude for the answer, Caulfield asked it to construct a Google query, which led him to actual funding numbers from the period. After some further research, he learned that most government spending prior to 1903 went not to the Wright Brothers but to Samuel Langley:
The LLM is used to give the lay of the land, but not to build a detailed map of it. It’s not that Claude is bad at facts in general — it is able to tell you about the Wright Brothers and about Langley quite well. But in finding elements of more detail, it is perhaps better to have the students transition to search.
Caulfield recommends using the LLM as a part of a larger habit, what Sam Wineberg calls “taking bearings”—in which you survey the landscape before diving into a research session (or debugging some code). In this way, LLMs can surface relevant questions to ask when you don’t know what to search for. You want to ask the right questions, and defer to traditional research and debugging to fill in specific knowledge. Once you have a complete picture of the problem, feeding that context back into your code assistant often yields a better result.
LLMs are potent tools and great at writing code. They excel at many routine tasks and can save you time and effort: setting up boilerplate code, refactoring and transformations, documenting behavior, suggesting optimizations, fixing bugs, and many more. One of my favorite use cases is building small personal tools that aren’t complicated but were previously time-prohibitive to create and maintain.
But you need to know if the code LLMs write is the right code. For that reason, a good rule is to have them work a level or two below your skill level. If you don’t fully understand the code they generate, take the opportunity to learn by studying the output and move to traditional research when necessary—then start from the beginning and write that code yourself. At the end of the day, solving the hard problems is what makes us engineers. If we approach LLMs with this mindset, they can be a useful tool for developers at all career stages.
No matter how experienced you are, it’s important to remain skeptical. AI is not magic. It’s not even a sharp tool. It’s a wildly destructive tool that can make you more productive but also wastes a lot of time and effort if wielded unconsciously.

 A frozen pond I photographed in early January 2024.
A frozen pond I photographed in early January 2024.

{kind=link}